 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSequential Strategic Classification with Multi-Stage Selective Classifiers
May 05, 2026Strategic classification studies the problem where self-interested individuals or agents manipulate their response to obtain favorable decision outcomes made by classifiers, typically turning to dishonest actions when they are less costly than genuine efforts. Prior works have demonstrated a fundamental inability to get out of this conundrum by only focusing on the design of a classifier. We note that prior work also heavily focuses on either one-shot settings or repeated interaction with the same classifier. Real-world decision making is often multi-stage, involving a sequence of potentially different classifiers as an agent progresses. This paper introduces a sequential, stochastic, multi-stage model of strategic classification, by capturing how agents adapt their behavior, through improvement actions (enhancing both observable features and true attributes) and gaming actions (enhancing only observable features), over multiple levels of classification with increasing difficulty as well as reward. For each level, we adopt a selective classifier that can abstain from making a prediction at low confidence. Consequently, a positive (resp. negative) outcome leads to promotion (resp. demotion) of the agent to the next higher (resp. lower) level, while abstention keeps the agent at the same level. We fully characterize the agent's optimal instantaneous action under selective classifiers and compare the long-term properties and utility of the agent repeatedly following an optimal myopic policy of either no-improvement (never choose the improvement action) or no-gaming (never choose the gaming action). We further examine design principles over the sequence of classifiers that yield higher long-term utility for the latter policy, thereby effectively incentivizing genuine effort in the long run.
Perceptual Flow Network for Visually Grounded Reasoning
May 04, 2026Despite the success of Large-Vision Language Models (LVLMs), general optimization objectives (e.g., standard MLE) fail to constrain visual trajectories, leading to language bias and hallucination. To mitigate this, current methods introduce geometric priors from visual experts as additional supervision. However, we observe that such supervision is typically suboptimal: it is biased toward geometric precision and offers limited reasoning utility. To bridge this gap, we propose Perceptual Flow Network (PFlowNet), which eschews rigid alignment with the expert priors and achieves interpretable yet more effective visual reasoning. Specifically, PFlowNet decouples perception from reasoning to establish a self-conditioned generation process. Based on this, it integrates multi-dimensional rewards with vicinal geometric shaping via variational reinforcement learning, thereby facilitating reasoning-oriented perceptual behaviors while preserving visual reliability. PFlowNet delivers a provable performance guarantee and competitive empirical results, particularly setting new SOTA records on V* Bench (90.6%) and MME-RealWorld-lite (67.0%).
TC-AE: Unlocking Token Capacity for Deep Compression Autoencoders
Apr 08, 2026We propose TC-AE, a ViT-based architecture for deep compression autoencoders. Existing methods commonly increase the channel number of latent representations to maintain reconstruction quality under high compression ratios. However, this strategy often leads to latent representation collapse, which degrades generative performance. Instead of relying on increasingly complex architectures or multi-stage training schemes, TC-AE addresses this challenge from the perspective of the token space, the key bridge between pixels and image latents, through two complementary innovations: Firstly, we study token number scaling by adjusting the patch size in ViT under a fixed latent budget, and identify aggressive token-to-latent compression as the key factor that limits effective scaling. To address this issue, we decompose token-to-latent compression into two stages, reducing structural information loss and enabling effective token number scaling for generation. Secondly, to further mitigate latent representation collapse, we enhance the semantic structure of image tokens via joint self-supervised training, leading to more generative-friendly latents. With these designs, TC-AE achieves substantially improved reconstruction and generative performance under deep compression. We hope our research will advance ViT-based tokenizer for visual generation.
AgentVLN: Towards Agentic Vision-and-Language Navigation
Mar 18, 2026Vision-and-Language Navigation (VLN) requires an embodied agent to ground complex natural-language instructions into long-horizon navigation in unseen environments. While Vision-Language Models (VLMs) offer strong 2D semantic understanding, current VLN systems remain constrained by limited spatial perception, 2D-3D representation mismatch, and monocular scale ambiguity. In this paper, we propose AgentVLN, a novel and efficient embodied navigation framework that can be deployed on edge computing platforms. We formulate VLN as a Partially Observable Semi-Markov Decision Process (POSMDP) and introduce a VLM-as-Brain paradigm that decouples high-level semantic reasoning from perception and planning via a plug-and-play skill library. To resolve multi-level representation inconsistency, we design a cross-space representation mapping that projects perception-layer 3D topological waypoints into the image plane, yielding pixel-aligned visual prompts for the VLM. Building on this bridge, we integrate a context-aware self-correction and active exploration strategy to recover from occlusions and suppress error accumulation over long trajectories. To further address the spatial ambiguity of instructions in unstructured environments, we propose a Query-Driven Perceptual Chain-of-Thought (QD-PCoT) scheme, enabling the agent with the metacognitive ability to actively seek geometric depth information. Finally, we construct AgentVLN-Instruct, a large-scale instruction-tuning dataset with dynamic stage routing conditioned on target visibility. Extensive experiments show that AgentVLN consistently outperforms prior state-of-the-art methods (SOTA) on long-horizon VLN benchmarks, offering a practical paradigm for lightweight deployment of next-generation embodied navigation models. Code: https://github.com/Allenxinn/AgentVLN.
Multi-Level Strategic Classification: Incentivizing Improvement through Promotion and Relegation Dynamics
Feb 11, 2026Strategic classification studies the problem where self-interested individuals or agents manipulate their response to obtain favorable decision outcomes made by classifiers, typically turning to dishonest actions when they are less costly than genuine efforts. While existing studies on sequential strategic classification primarily focus on optimizing dynamic classifier weights, we depart from these weight-centric approaches by analyzing the design of classifier thresholds and difficulty progression within a multi-level promotion-relegation framework. Our model captures the critical inter-temporal incentives driven by an agent's farsightedness, skill retention, and a leg-up effect where qualification and attainment can be self-reinforcing. We characterize the agent's optimal long-term strategy and demonstrate that a principal can design a sequence of thresholds to effectively incentivize honest effort. Crucially, we prove that under mild conditions, this mechanism enables agents to reach arbitrarily high levels solely through genuine improvement efforts.
ARGenSeg: Image Segmentation with Autoregressive Image Generation Model
Oct 23, 2025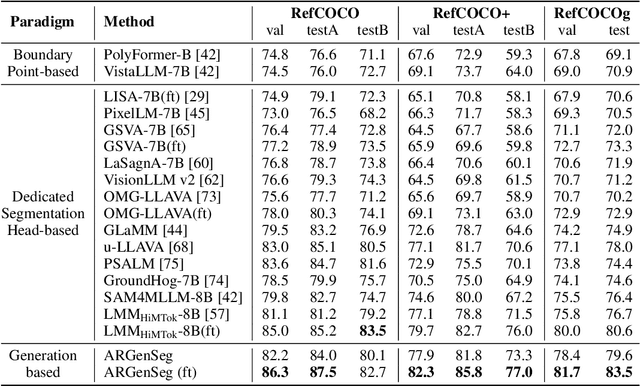
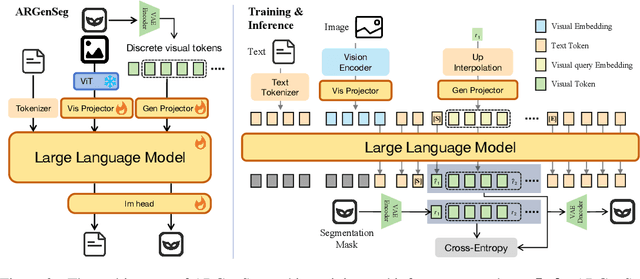


We propose a novel AutoRegressive Generation-based paradigm for image Segmentation (ARGenSeg), achieving multimodal understanding and pixel-level perception within a unified framework. Prior works integrating image segmentation into multimodal large language models (MLLMs) typically employ either boundary points representation or dedicated segmentation heads. These methods rely on discrete representations or semantic prompts fed into task-specific decoders, which limits the ability of the MLLM to capture fine-grained visual details. To address these challenges, we introduce a segmentation framework for MLLM based on image generation, which naturally produces dense masks for target objects. We leverage MLLM to output visual tokens and detokenize them into images using an universal VQ-VAE, making the segmentation fully dependent on the pixel-level understanding of the MLLM. To reduce inference latency, we employ a next-scale-prediction strategy to generate required visual tokens in parallel. Extensive experiments demonstrate that our method surpasses prior state-of-the-art approaches on multiple segmentation datasets with a remarkable boost in inference speed, while maintaining strong understanding capabilities.
Vision-Centric Activation and Coordination for Multimodal Large Language Models
Oct 16, 2025Multimodal large language models (MLLMs) integrate image features from visual encoders with LLMs, demonstrating advanced comprehension capabilities. However, mainstream MLLMs are solely supervised by the next-token prediction of textual tokens, neglecting critical vision-centric information essential for analytical abilities. To track this dilemma, we introduce VaCo, which optimizes MLLM representations through Vision-Centric activation and Coordination from multiple vision foundation models (VFMs). VaCo introduces visual discriminative alignment to integrate task-aware perceptual features extracted from VFMs, thereby unifying the optimization of both textual and visual outputs in MLLMs. Specifically, we incorporate the learnable Modular Task Queries (MTQs) and Visual Alignment Layers (VALs) into MLLMs, activating specific visual signals under the supervision of diverse VFMs. To coordinate representation conflicts across VFMs, the crafted Token Gateway Mask (TGM) restricts the information flow among multiple groups of MTQs. Extensive experiments demonstrate that VaCo significantly improves the performance of different MLLMs on various benchmarks, showcasing its superior capabilities in visual comprehension.
Ming-Omni: A Unified Multimodal Model for Perception and Generation
Jun 11, 2025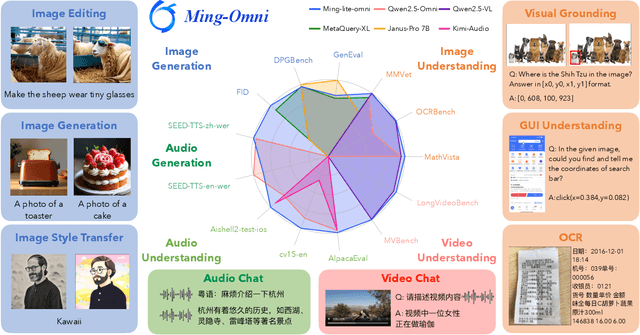
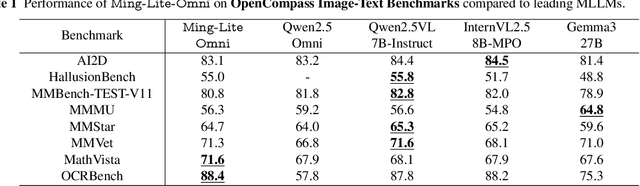
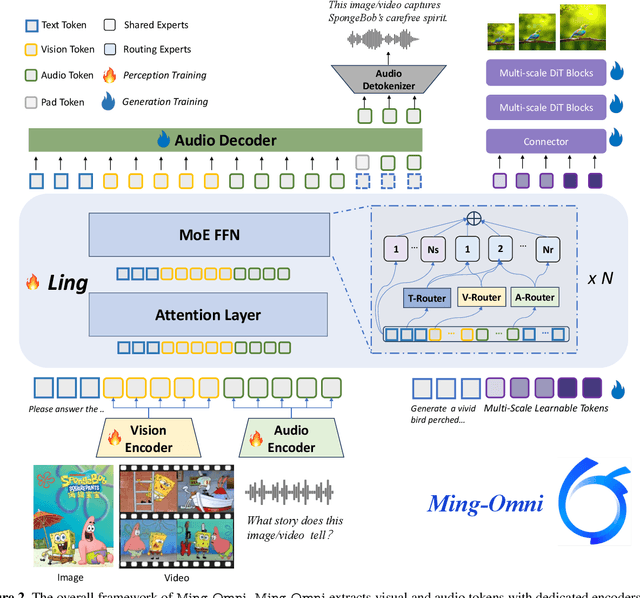
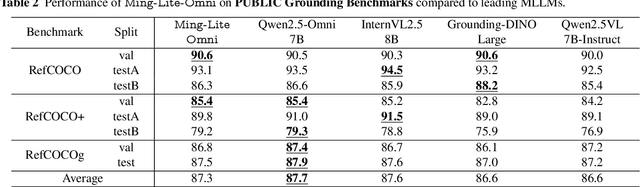
We propose Ming-Omni, a unified multimodal model capable of processing images, text, audio, and video, while demonstrating strong proficiency in both speech and image generation. Ming-Omni employs dedicated encoders to extract tokens from different modalities, which are then processed by Ling, an MoE architecture equipped with newly proposed modality-specific routers. This design enables a single model to efficiently process and fuse multimodal inputs within a unified framework, thereby facilitating diverse tasks without requiring separate models, task-specific fine-tuning, or structural redesign. Importantly, Ming-Omni extends beyond conventional multimodal models by supporting audio and image generation. This is achieved through the integration of an advanced audio decoder for natural-sounding speech and Ming-Lite-Uni for high-quality image generation, which also allow the model to engage in context-aware chatting, perform text-to-speech conversion, and conduct versatile image editing. Our experimental results showcase Ming-Omni offers a powerful solution for unified perception and generation across all modalities. Notably, our proposed Ming-Omni is the first open-source model we are aware of to match GPT-4o in modality support, and we release all code and model weights to encourage further research and development in the community.
Advancing 3D Medical Image Segmentation: Unleashing the Potential of Planarian Neural Networks in Artificial Intelligence
May 07, 2025Our study presents PNN-UNet as a method for constructing deep neural networks that replicate the planarian neural network (PNN) structure in the context of 3D medical image data. Planarians typically have a cerebral structure comprising two neural cords, where the cerebrum acts as a coordinator, and the neural cords serve slightly different purposes within the organism's neurological system. Accordingly, PNN-UNet comprises a Deep-UNet and a Wide-UNet as the nerve cords, with a densely connected autoencoder performing the role of the brain. This distinct architecture offers advantages over both monolithic (UNet) and modular networks (Ensemble-UNet). Our outcomes on a 3D MRI hippocampus dataset, with and without data augmentation, demonstrate that PNN-UNet outperforms the baseline UNet and several other UNet variants in image segmentation.
Ming-Lite-Uni: Advancements in Unified Architecture for Natural Multimodal Interaction
May 05, 2025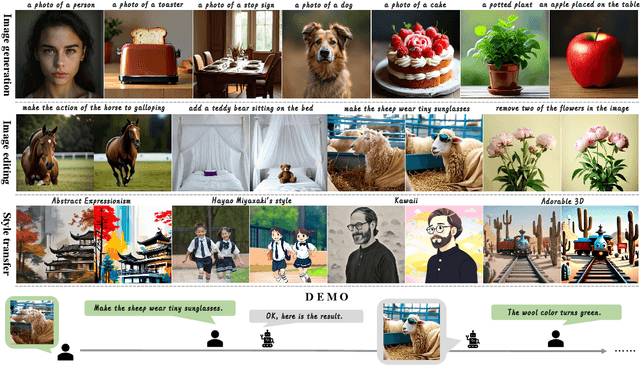

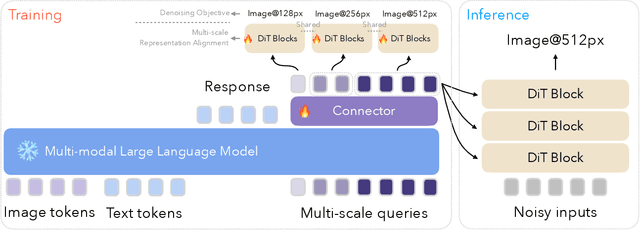
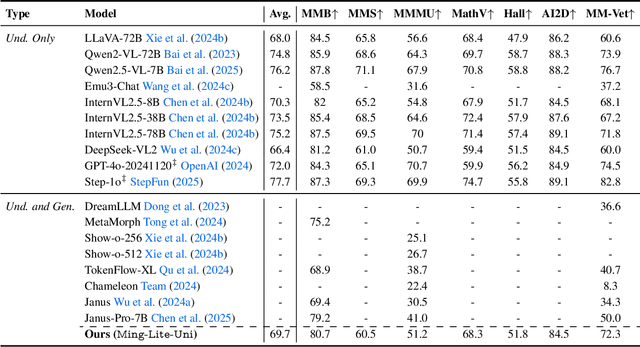
We introduce Ming-Lite-Uni, an open-source multimodal framework featuring a newly designed unified visual generator and a native multimodal autoregressive model tailored for unifying vision and language. Specifically, this project provides an open-source implementation of the integrated MetaQueries and M2-omni framework, while introducing the novel multi-scale learnable tokens and multi-scale representation alignment strategy. By leveraging a fixed MLLM and a learnable diffusion model, Ming-Lite-Uni enables native multimodal AR models to perform both text-to-image generation and instruction based image editing tasks, expanding their capabilities beyond pure visual understanding. Our experimental results demonstrate the strong performance of Ming-Lite-Uni and illustrate the impressive fluid nature of its interactive process. All code and model weights are open-sourced to foster further exploration within the community. Notably, this work aligns with concurrent multimodal AI milestones - such as ChatGPT-4o with native image generation updated in March 25, 2025 - underscoring the broader significance of unified models like Ming-Lite-Uni on the path toward AGI. Ming-Lite-Uni is in alpha stage and will soon be further refined.